GCU
Note: This blog post is about Maheen's Senior Project. Since she graduated a year before the rest of the us (who are '12 students), her Project was completed earlier this year.
When a camera takes a picture, it’s “flattening” the world it’s viewing. So while it might be pretty obvious to us looking at this picture that the building is upright, and the ground is not, it is not that obvious to a computer. It does not know what buildings are, what trees are, what the ground is, what the sky is, and how all of these usually relate to one another. To your computer, this picture on the left is a two dimensional matrix. Without knowing anything about the three dimensional scene this picture captured, it would not be possible for your computer to infer anything about the nature of that scene. That information has been lost in the flattening.
Now, given certain constraints on the scene that has been flattened, it’s possible to recover the information your picture “flattened” out. Here are some examples of “unflattening” I really like.
There is research being done on this problem of “unflattening” a picture– more commonly known as single view 2D to 3D reconstruction - in the LUMS Computer Vision Lab. The constraints placed on the scene to be rectified were two. First, that the scene comprised of planes that were not discontinuous – so natural objects such as animals, mountains, plants, etc, are out ruled. Secondly, that each of these planes had some orthogonal lines on it, for example, a house with windows on each side. Using these two constraints (and some user input), single view reconstruction is possible.
Our senior year project was about doing the same thing, 3D reconstruction, but using information obtained from multiple images as opposed to a single image. By using multiple images we could create reconstructions that were more complete and real to life, since we can know what the object looks like from multiple angles and not just one. At the same time, we would also need to know how these photographs relate to one another so that we could join their respective three dimensional reconstructions together; there would have to be some kind of overlap between the images we use.
Now, we’ve assumed that our individual single view reconstructions work. Hence, we know that the constraints under which single view reconstruction is successful hold: we know that the scene we’re reconstructing comprises of planes that are not discontinuous, and that each of these planes has some orthogonal lines on them. By knowing this, we know that bringing two models together is just a matter of fusing together the two planes that are common between these two models. By common I mean both these planes are separate reconstructions of the same plane in the real world (that’s the one we live in I think).
It turns out that the minimum number of point correspondences you need to fuse together two planes is three. And that’s how much overlap you need in your photographs: three points. That’s it.
When a camera takes a picture, it’s “flattening” the world it’s viewing. So while it might be pretty obvious to us looking at this picture that the building is upright, and the ground is not, it is not that obvious to a computer. It does not know what buildings are, what trees are, what the ground is, what the sky is, and how all of these usually relate to one another. To your computer, this picture on the left is a two dimensional matrix. Without knowing anything about the three dimensional scene this picture captured, it would not be possible for your computer to infer anything about the nature of that scene. That information has been lost in the flattening.
Now, given certain constraints on the scene that has been flattened, it’s possible to recover the information your picture “flattened” out. Here are some examples of “unflattening” I really like.
There is research being done on this problem of “unflattening” a picture– more commonly known as single view 2D to 3D reconstruction - in the LUMS Computer Vision Lab. The constraints placed on the scene to be rectified were two. First, that the scene comprised of planes that were not discontinuous – so natural objects such as animals, mountains, plants, etc, are out ruled. Secondly, that each of these planes had some orthogonal lines on it, for example, a house with windows on each side. Using these two constraints (and some user input), single view reconstruction is possible.
Our senior year project was about doing the same thing, 3D reconstruction, but using information obtained from multiple images as opposed to a single image. By using multiple images we could create reconstructions that were more complete and real to life, since we can know what the object looks like from multiple angles and not just one. At the same time, we would also need to know how these photographs relate to one another so that we could join their respective three dimensional reconstructions together; there would have to be some kind of overlap between the images we use.
Now, we’ve assumed that our individual single view reconstructions work. Hence, we know that the constraints under which single view reconstruction is successful hold: we know that the scene we’re reconstructing comprises of planes that are not discontinuous, and that each of these planes has some orthogonal lines on them. By knowing this, we know that bringing two models together is just a matter of fusing together the two planes that are common between these two models. By common I mean both these planes are separate reconstructions of the same plane in the real world (that’s the one we live in I think).
It turns out that the minimum number of point correspondences you need to fuse together two planes is three. And that’s how much overlap you need in your photographs: three points. That’s it.


Of course, once you’ve fused together your planes, you will not get a reconstruction that’s perfect. Your single view reconstructions (SVR) were not perfect to begin with, so your multi-view reconstruction (MVR) will also be imperfect, and it will only get more imperfect with every additional SVR you use.
Oh dear.
Oh dear.

AnimalPictures1.com
Conversely, the more SVRs we use, the more information we have about the structure we’re reconstructing. So, shouldn’t our MVR get better, and not worse? Well, yes. But only if we use this extra information.
We used the three (or more) common points to make all six of the points lie on the same plane. However, just because these points now lie on the same plane does not mean that these points themselves have fused together. We had six points on two separate planes to begin with. We will now have six points on the same plane – where as ideally, since these points represent the same three points in the real world, we should have three. Therefore, we try to construct our SVRs in such a way that the distance between corresponding points after stitching is minimized, that our six points come as close as possible to becoming three points.
However, if we remodel our SVRs to minimize common points’ distance only, we are also running the risk of creating worse models. Why? Because we are no longer taking in to account the nature of the scene we were reconstructing in the first place. In other words, we are not making sure that each plane has some orthogonal lines, and that planes are continuous and intersect each other properly. It is the interplay of all three of these factors that would create an accurate and realistic multi view reconstruction of the scene we plan to reconstruct.
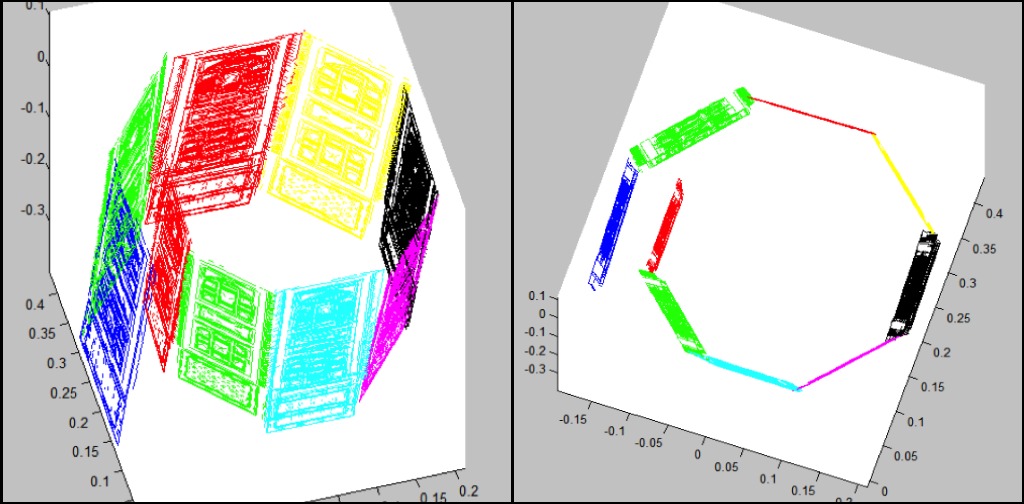
Turns out this interplay is not that easy to figure out. Determining which factors need to be given relatively more weight depends on the quality of our SVRs, which in turn depends on the pictures and what they are capturing – and that’s the problem in the first place: we don’t know what exactly we’re taking pictures of. So we need to change our solution so that the question of weights does not come up, and that is what I am working on right now. However, by the end of our senior year, we hadn’t discovered this problem. We were playing around with weights and generating models that made us happy to look at. Here’s an example. The first two images are of what we were trying to stitch together. We were being lazy, so we just stitched multiple SVRs from this picture rather than multiple SVRs from different pictures. The second two are what the results of stitching looked like when we stitched the models together without optimizing. And the last is what we got after we took common points’ distance in to account and tried to minimize it.
We used the three (or more) common points to make all six of the points lie on the same plane. However, just because these points now lie on the same plane does not mean that these points themselves have fused together. We had six points on two separate planes to begin with. We will now have six points on the same plane – where as ideally, since these points represent the same three points in the real world, we should have three. Therefore, we try to construct our SVRs in such a way that the distance between corresponding points after stitching is minimized, that our six points come as close as possible to becoming three points.
However, if we remodel our SVRs to minimize common points’ distance only, we are also running the risk of creating worse models. Why? Because we are no longer taking in to account the nature of the scene we were reconstructing in the first place. In other words, we are not making sure that each plane has some orthogonal lines, and that planes are continuous and intersect each other properly. It is the interplay of all three of these factors that would create an accurate and realistic multi view reconstruction of the scene we plan to reconstruct.
Turns out this interplay is not that easy to figure out. Determining which factors need to be given relatively more weight depends on the quality of our SVRs, which in turn depends on the pictures and what they are capturing – and that’s the problem in the first place: we don’t know what exactly we’re taking pictures of. So we need to change our solution so that the question of weights does not come up, and that is what I am working on right now. However, by the end of our senior year, we hadn’t discovered this problem. We were playing around with weights and generating models that made us happy to look at. Here’s an example. The first two images are of what we were trying to stitch together. We were being lazy, so we just stitched multiple SVRs from this picture rather than multiple SVRs from different pictures. The second two are what the results of stitching looked like when we stitched the models together without optimizing. And the last is what we got after we took common points’ distance in to account and tried to minimize it.



Whenever I tell people about my senior project, they ask me of what practical use it is. Frankly, I don’t know. I’m sure somewhere someone will find this work useful, and not just to make an iPhone or Android application. Maybe historians would use it, or architects would. What difference does it make? It’s an interesting problem, and we tried to solve it. If it has any practical value, that’s a bonus. Who knows what practical value anything will eventually have? Now here’s the video I wrote this paragraph for:
Maheen
 RSS Feed
RSS Feed